Discrete Probability
beads <- rep( c('red', 'blue'), times = c(2,3))
beads
## [1] "red" "red" "blue" "blue" "blue"
Produces a random outcome
## [1] "red"
Goal is to repeat the experiment a large number of times to give an accurate probability if the experiment was repeated infinity.
We can use a Monte Carlo simulation. To do this, we can use the replicate() function to repeat the same task any number of times we want.
B <- 10000
events <- replicate(B, sample(beads,1))
We can create a table of our outcomes using the table() function as well as see the proportion by using prop.table().
## events
## blue red
## 5918 4082
## events
## blue red
## 0.5918 0.4082
We actually don’t have to use the replicate() function for this example because the sample() function actually has an argument that permits us to pick more than one element form the urn with replacement.
events <- sample(beads, B, replace=TRUE)
prop.table(table(events))
## events
## blue red
## 0.6045 0.3955
In R, applying the mean() function to a logical vector returns the proportion of elements that are TRUE. It is very common to use the mean() function in this way to calculate probabilities and we will do so throughout the course.
Suppose you have the vector beads from a previous video:
beads <- rep(c("red", "blue"), times = c(2,3))
beads
## [1] "red" "red" "blue" "blue" "blue"
To find the probability of drawing a blue bead at random, you can run:
## [1] 0.6
This code is broken down into steps inside R. First, R evaluates the logical statement beads == "blue", which generates the vector:
FALSE FALSE TRUE TRUE TRUE
When the mean function is applied, R coerces the logical values to numeric values, changing TRUE to 1 and FALSE to 0:
0 0 1 1 1
The mean of the zeros and ones thus gives the proportion of TRUE values. As we have learned and will continue to see, probabilities are directly related to the proportion of events that satisfy a requirement.
Probability distributions
Defining a distribution for categorical outcomes is straight forward. We assign a probability to each category.
Two events are independent if the outcome of one does not affect the outcome of the other e.g. coin toss or picking beads with replacement.
When events are not independent, conditional probabilities are useful and necessary to make correct calculations
To calculate the probability that the second card dealt from a deck of cards is a king, given that the first card dealt was a king. The | pipe means given that or conditional on
Pr(Card 2 is a king) | Card 1 is a king) = 3/51
If the probability of A and B are independent, you can express the probability of A like this:
Pr(A|B)=Pr(A)
It doesn’t matter what the probability of B is in this example because the probabilities are independent.
If we want to know the probability of A and B occurring, we can use the multiplication rule. The probability of A and and B is equal to the probability of A multiplied by the probability of B given that A already happened.
Pr(A and B) = Pr(A)*Pr(B|A)
In blackjack, you can calculate the probability of you first getting an Ace then having the next card be a face card or a 10 using the following:
Pr(Ace and face) = Pr(Ace)*Pr(Face|Ace)
## [1] 0.02413273
So, the probability of A and B and C is equal to the probability of A times the probability of B given that A happened times the probability of C given that A and B happened
Pr(A and B and C) = Pr(A)*Pr(B|A)*Pr(C|A and B)
One ball will be drawn at random from a box containing: 3 cyan balls, 5 magenta balls, and 7 yellow balls.
box <- rep( c('cyan', 'magenta', 'yellow'), times = c(3,5,7))
box
## [1] "cyan" "cyan" "cyan" "magenta" "magenta" "magenta" "magenta"
## [8] "magenta" "yellow" "yellow" "yellow" "yellow" "yellow" "yellow"
## [15] "yellow"
Instead of taking just one draw, consider taking two draws. You take the second draw without returning the first draw to the box. We call this sampling without replacement.
## [1] 0.1714286
Now repeat the experiment, but this time, after taking the first draw and recording the color, return it back to the box and shake the box. We call this sampling with replacement.
What is the probability that the first draw is cyan and that the second draw is not cyan?
## [1] 0.16
Combinations and Permutations
# joining strings with paste
number <- "Three"
suit <- "Hearts"
paste(number, suit)
## [1] "Three Hearts"
# joining vectors element-wise with paste
paste(letters[1:5], as.character(1:5))
## [1] "a 1" "b 2" "c 3" "d 4" "e 5"
The function expland.grid() gives us all combinations of 2 lists.
expand.grid(pants = c("blue", "black"), shirt = c("white", "grey", "plaid"))
## pants shirt
## 1 blue white
## 2 black white
## 3 blue grey
## 4 black grey
## 5 blue plaid
## 6 black plaid
To generate a deck of cards:
suits <- c("Diamonds", "Clubs", "Hearts", "Spades")
numbers <- c("Ace", "Deuce", "Three", "Four", "Five", "Six", "Seven", "Eight", "Nine", "Ten", "Jack", "Queen", "King")
deck <- expand.grid(number = numbers, suit = suits)
deck <- paste(deck$number, deck$suit)
To find the probability of drawing a king:
kings <- paste("King", suits)
mean(deck %in% kings)
## [1] 0.07692308
What is the conditional probability of the second card is a king?
The permutations() function computes, for any list of size ‘n’ all the different ways we can select ‘r’ items.
library(gtools)
# This will calculate all the ways you can choose 2 numbers from a list of 1-5.
permutations(5,2)
## [,1] [,2]
## [1,] 1 2
## [2,] 1 3
## [3,] 1 4
## [4,] 1 5
## [5,] 2 1
## [6,] 2 3
## [7,] 2 4
## [8,] 2 5
## [9,] 3 1
## [10,] 3 2
## [11,] 3 4
## [12,] 3 5
## [13,] 4 1
## [14,] 4 2
## [15,] 4 3
## [16,] 4 5
## [17,] 5 1
## [18,] 5 2
## [19,] 5 3
## [20,] 5 4
To compute all the possible ways that you can choose 2 cards when the order matters we can type:
# We have 52 cards, we will choose 2, and we will select them from the vector of our card names
hands <- permutations(52,2, v = deck)
first_card <- hands[,1]
second_card <- hands[,2]
# How many cases is the first card a king?
sum(first_card %in% kings)
## [1] 204
# We ask how what fraction of these 204 also have a king in the second card?
sum(first_card %in% kings & second_card %in% kings) / sum(first_card %in% kings)
## [1] 0.05882353
What if the order does not matter? Use the combinations() function since the order doesn’t matter.
Compare the two functions
## [,1] [,2]
## [1,] 1 2
## [2,] 1 3
## [3,] 2 1
## [4,] 2 3
## [5,] 3 1
## [6,] 3 2
## [,1] [,2]
## [1,] 1 2
## [2,] 1 3
## [3,] 2 3
Define a vector that includes all the aces, avector that includes all the face cards and 10’s, then generate all the combinations of picking 2 cards out of 52.
aces <- paste("Ace", suits)
facecard <- c("King", "Queen", "Jack", "Ten")
facecard <- expand.grid(number = facecard, suit = suits)
facecard <- paste(facecard$number, facecard$suit)
hands <- combinations(52, 2, v=deck) # all possible hands
# probability of a natural 21 given that the ace is listed first in `combinations`
mean(hands[,1] %in% aces & hands[,2] %in% facecard)
## [1] 0.04826546
You can also use a Monte Carlo simulation to calculate the probability of getting blackjack on the first 2 cards.
Use the sample() function to draw cards without replacement
hand <- sample(deck, 2)
hand
## [1] "Four Spades" "Six Clubs"
# code for B=10,000 hands of blackjack
B <- 10000
results <- replicate(B, {
hand <- sample(deck, 2)
(hand[1] %in% aces & hand[2] %in% facecard) | (hand[2] %in% aces & hand[1] %in% facecard)
})
mean(results)
## [1] 0.0486
The birthday problem
If you are in a classroom with 50 people, assuming it is a randomly selected group, what is the chance that at least 2 people have the same birthday?
We will calculate this later, but first we can use the Monte Carlo simulation.
n <- 50
calendar <- 1:365
bdays <- sample(calendar, n, replace=TRUE)
To check to see if two people have the same birthday, use the function duplicated() which returns TRUE if any element of a vector has already appeared in that vector.
## [1] TRUE
b <- 10000
results <- replicate(B,{
bdays <- sample(calendar, n, replace=TRUE)
any(duplicated(bdays))
})
Take the mean to determine how likely it is for two people to have the same birthday
## [1] 0.9669
sapply
sapply() allows us to perform element-wise operations on any function.
This will apply square root to each element of x. You actually don’t need to do this because sqrt() already operates on a vector element by element, but some functions do not.
x <- 1:10
sapply(x, sqrt)
## [1] 1.000000 1.414214 1.732051 2.000000 2.236068 2.449490 2.645751 2.828427
## [9] 3.000000 3.162278
If you wanted to bet on the chances that 2 people have the same birthday in a group of people, you can use a Monte Carlo simulation. We will define a function to cacluate the probability of shared bdays across n people.
compute_prob <- function(n, B = 10000) {
same_day <- replicate(B, {
bdays <- sample(1:365, n, replace = TRUE)
any(duplicated(bdays))
})
mean(same_day)
}
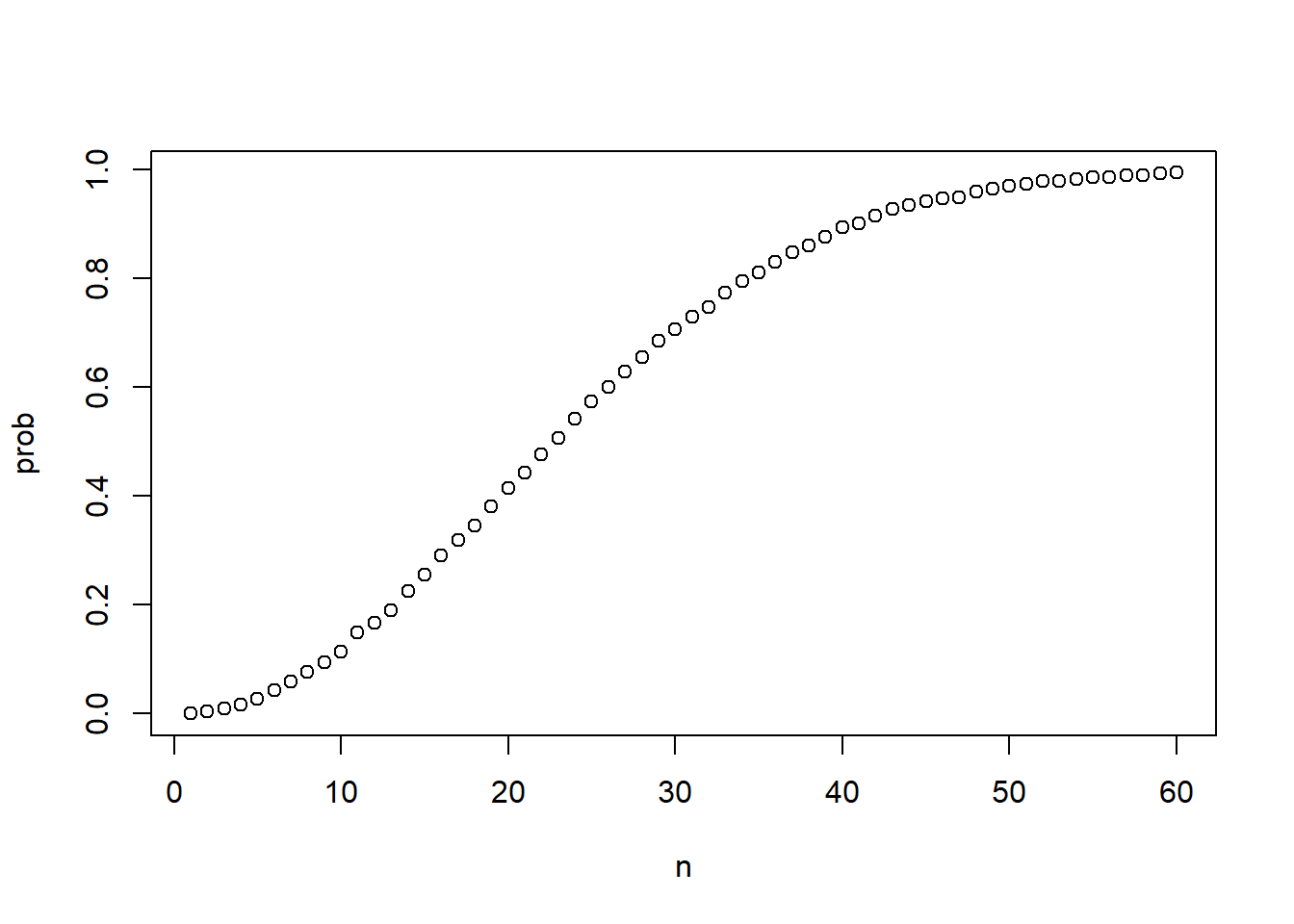
n <- seq(1, 60)
prob <- sapply(n, compute_prob)
If we wanted to compute the exact value instead of using a Monte Carlo Simulation we can calculate the exact value. Instead of calculating the probability of it happening, it is faster to calculate the probability of it not happening then use the multiplication rule.
Starting with person 1, the probability that they have a unique birthday is 1.
We can compute the probability of shared birthdays mathematically:
exact_prob <- function(n){
prob_unique <- seq(365, 365-n+1)/365
# the probabilty of an event happening is 1 minus the probability of the event not happening
1 - prod( prob_unique)
}
eprob <- sapply(n, exact_prob)
# Compare monte carlo plot to exact probabilty plot
plot(n, prob)
lines(n, eprob, col = 'red')
LS0tDQp0aXRsZTogIlByb2JhYmlsaXR5Ig0Kb3V0cHV0Og0KICBodG1sX2RvY3VtZW50OiANCiAgICB0b2M6IHllcw0KICAgIHRvY19kZXB0aDogMg0KICAgIHRvY19mbG9hdDogeWVzDQogICAgaGlnaGxpZ2h0OiB6ZW5idXJuDQogICAgY29kZV9kb3dubG9hZDogdHJ1ZQ0KICAgIGluY2x1ZGVzOg0KICAgICAgaW5faGVhZGVyOiBoZWFkZXIuaHRtbA0KLS0tDQoNCg0KIyBEaXNjcmV0ZSBQcm9iYWJpbGl0eQ0KDQpgYGB7cn0NCmJlYWRzIDwtIHJlcCggYygncmVkJywgJ2JsdWUnKSwgdGltZXMgPSBjKDIsMykpDQpiZWFkcw0KYGBgDQpQcm9kdWNlcyBhIHJhbmRvbSBvdXRjb21lDQpgYGB7cn0NCnNhbXBsZSggYmVhZHMsMSkNCmBgYA0KDQpHb2FsIGlzIHRvIHJlcGVhdCB0aGUgZXhwZXJpbWVudCBhIGxhcmdlIG51bWJlciBvZiB0aW1lcyB0byBnaXZlIGFuIGFjY3VyYXRlIHByb2JhYmlsaXR5IGlmIHRoZSBleHBlcmltZW50IHdhcyByZXBlYXRlZCBpbmZpbml0eS4gDQoNCldlIGNhbiB1c2UgYSBNb250ZSBDYXJsbyBzaW11bGF0aW9uLiBUbyBkbyB0aGlzLCB3ZSBjYW4gdXNlIHRoZSBgcmVwbGljYXRlKClgIGZ1bmN0aW9uIHRvIHJlcGVhdCB0aGUgc2FtZSB0YXNrIGFueSBudW1iZXIgb2YgdGltZXMgd2Ugd2FudC4NCg0KYGBge3J9DQpCIDwtIDEwMDAwDQpldmVudHMgPC0gcmVwbGljYXRlKEIsIHNhbXBsZShiZWFkcywxKSkNCmBgYA0KDQpXZSBjYW4gY3JlYXRlIGEgdGFibGUgb2Ygb3VyIG91dGNvbWVzIHVzaW5nIHRoZSBgdGFibGUoKWAgZnVuY3Rpb24gYXMgd2VsbCBhcyBzZWUgdGhlIHByb3BvcnRpb24gYnkgdXNpbmcgYHByb3AudGFibGUoKWAuDQpgYGB7cn0NCnRhYiA8LSB0YWJsZShldmVudHMpDQp0YWINCnByb3AudGFibGUodGFiKQ0KYGBgDQoNCldlIGFjdHVhbGx5IGRvbid0IGhhdmUgdG8gdXNlIHRoZSBgcmVwbGljYXRlKClgIGZ1bmN0aW9uIGZvciB0aGlzIGV4YW1wbGUgYmVjYXVzZSB0aGUgYHNhbXBsZSgpYCBmdW5jdGlvbiBhY3R1YWxseSBoYXMgYW4gYXJndW1lbnQgdGhhdCBwZXJtaXRzIHVzIHRvIHBpY2sgbW9yZSB0aGFuIG9uZSBlbGVtZW50IGZvcm0gdGhlIHVybiAqKndpdGggcmVwbGFjZW1lbnQqKi4gDQoNCmBgYHtyfQ0KZXZlbnRzIDwtIHNhbXBsZShiZWFkcywgQiwgcmVwbGFjZT1UUlVFKQ0KcHJvcC50YWJsZSh0YWJsZShldmVudHMpKQ0KYGBgDQoNCkluIFIsIGFwcGx5aW5nIHRoZSBgbWVhbigpYCBmdW5jdGlvbiB0byBhIGxvZ2ljYWwgdmVjdG9yIHJldHVybnMgdGhlIHByb3BvcnRpb24gb2YgZWxlbWVudHMgdGhhdCBhcmUgKlRSVUUqLiBJdCBpcyB2ZXJ5IGNvbW1vbiB0byB1c2UgdGhlIGBtZWFuKClgIGZ1bmN0aW9uIGluIHRoaXMgd2F5IHRvIGNhbGN1bGF0ZSBwcm9iYWJpbGl0aWVzIGFuZCB3ZSB3aWxsIGRvIHNvIHRocm91Z2hvdXQgdGhlIGNvdXJzZS4NCg0KU3VwcG9zZSB5b3UgaGF2ZSB0aGUgdmVjdG9yIGJlYWRzIGZyb20gYSBwcmV2aW91cyB2aWRlbzoNCg0KYGBge3J9DQpiZWFkcyA8LSByZXAoYygicmVkIiwgImJsdWUiKSwgdGltZXMgPSBjKDIsMykpDQpiZWFkcw0KYGBgDQoNClRvIGZpbmQgdGhlIHByb2JhYmlsaXR5IG9mIGRyYXdpbmcgYSBibHVlIGJlYWQgYXQgcmFuZG9tLCB5b3UgY2FuIHJ1bjoNCg0KYGBge3J9DQptZWFuKGJlYWRzID09ICJibHVlIikNCmBgYA0KDQpUaGlzIGNvZGUgaXMgYnJva2VuIGRvd24gaW50byBzdGVwcyBpbnNpZGUgUi4gRmlyc3QsIFIgZXZhbHVhdGVzIHRoZSBsb2dpY2FsIHN0YXRlbWVudCBgYmVhZHMgPT0gImJsdWUiYCwgd2hpY2ggZ2VuZXJhdGVzIHRoZSB2ZWN0b3I6DQoNCmBGQUxTRSBGQUxTRSBUUlVFIFRSVUUgVFJVRWANCg0KV2hlbiB0aGUgbWVhbiBmdW5jdGlvbiBpcyBhcHBsaWVkLCBSIGNvZXJjZXMgdGhlIGxvZ2ljYWwgdmFsdWVzIHRvIG51bWVyaWMgdmFsdWVzLCBjaGFuZ2luZyBUUlVFIHRvIDEgYW5kIEZBTFNFIHRvIDA6DQoNCmAwIDAgMSAxIDFgDQoNClRoZSBtZWFuIG9mIHRoZSB6ZXJvcyBhbmQgb25lcyB0aHVzIGdpdmVzIHRoZSBwcm9wb3J0aW9uIG9mIFRSVUUgdmFsdWVzLiBBcyB3ZSBoYXZlIGxlYXJuZWQgYW5kIHdpbGwgY29udGludWUgdG8gc2VlLCBwcm9iYWJpbGl0aWVzIGFyZSBkaXJlY3RseSByZWxhdGVkIHRvIHRoZSBwcm9wb3J0aW9uIG9mIGV2ZW50cyB0aGF0IHNhdGlzZnkgYSByZXF1aXJlbWVudC4NCg0KIyBQcm9iYWJpbGl0eSBkaXN0cmlidXRpb25zDQoNCkRlZmluaW5nIGEgZGlzdHJpYnV0aW9uIGZvciBjYXRlZ29yaWNhbCBvdXRjb21lcyBpcyBzdHJhaWdodCBmb3J3YXJkLiBXZSBhc3NpZ24gYSBwcm9iYWJpbGl0eSB0byBlYWNoIGNhdGVnb3J5Lg0KDQpUd28gZXZlbnRzIGFyZSBpbmRlcGVuZGVudCBpZiB0aGUgb3V0Y29tZSBvZiBvbmUgZG9lcyBub3QgYWZmZWN0IHRoZSBvdXRjb21lIG9mIHRoZSBvdGhlciBlLmcuIGNvaW4gdG9zcyBvciBwaWNraW5nIGJlYWRzIHdpdGggcmVwbGFjZW1lbnQuDQoNCldoZW4gZXZlbnRzIGFyZSBub3QgaW5kZXBlbmRlbnQsIGNvbmRpdGlvbmFsIHByb2JhYmlsaXRpZXMgYXJlIHVzZWZ1bCBhbmQgbmVjZXNzYXJ5IHRvIG1ha2UgY29ycmVjdCBjYWxjdWxhdGlvbnMNCg0KVG8gY2FsY3VsYXRlIHRoZSBwcm9iYWJpbGl0eSB0aGF0IHRoZSBzZWNvbmQgY2FyZCBkZWFsdCBmcm9tIGEgZGVjayBvZiBjYXJkcyBpcyBhIGtpbmcsIGdpdmVuIHRoYXQgdGhlIGZpcnN0IGNhcmQgZGVhbHQgd2FzIGEga2luZy4gVGhlIGB8YCBwaXBlIG1lYW5zIGBnaXZlbiB0aGF0IG9yIGNvbmRpdGlvbmFsIG9uYA0KDQpgIFByKENhcmQgMiBpcyBhIGtpbmcpIHwgQ2FyZCAxIGlzIGEga2luZykgPSAzLzUxYCAgICANCg0KSWYgdGhlIHByb2JhYmlsaXR5IG9mIEEgYW5kIEIgYXJlIGluZGVwZW5kZW50LCB5b3UgY2FuIGV4cHJlc3MgdGhlIHByb2JhYmlsaXR5IG9mIEEgbGlrZSB0aGlzOg0KDQpgUHIoQXxCKT1QcihBKWANCg0KSXQgZG9lc24ndCBtYXR0ZXIgd2hhdCB0aGUgcHJvYmFiaWxpdHkgb2YgQiBpcyBpbiB0aGlzIGV4YW1wbGUgYmVjYXVzZSB0aGUgcHJvYmFiaWxpdGllcyBhcmUgaW5kZXBlbmRlbnQuIA0KDQpJZiB3ZSB3YW50IHRvIGtub3cgdGhlIHByb2JhYmlsaXR5IG9mIEEgYW5kIEIgb2NjdXJyaW5nLCB3ZSBjYW4gdXNlIHRoZSAqKm11bHRpcGxpY2F0aW9uIHJ1bGUqKi4gVGhlIHByb2JhYmlsaXR5IG9mIEEgYW5kIGFuZCBCIGlzIGVxdWFsIHRvIHRoZSBwcm9iYWJpbGl0eSBvZiBBIG11bHRpcGxpZWQgYnkgdGhlIHByb2JhYmlsaXR5IG9mIEIgZ2l2ZW4gdGhhdCBBIGFscmVhZHkgaGFwcGVuZWQuDQoNCmBQcihBIGFuZCBCKSA9IFByKEEpKlByKEJ8QSlgDQoNCkluIGJsYWNramFjaywgeW91IGNhbiBjYWxjdWxhdGUgdGhlIHByb2JhYmlsaXR5IG9mIHlvdSBmaXJzdCBnZXR0aW5nIGFuICpBY2UqIHRoZW4gaGF2aW5nIHRoZSBuZXh0IGNhcmQgYmUgYSAqZmFjZSogY2FyZCBvciBhICoxMCogdXNpbmcgdGhlIGZvbGxvd2luZzoNCg0KYFByKEFjZSBhbmQgZmFjZSkgPSBQcihBY2UpKlByKEZhY2V8QWNlKWANCg0KYGBge3J9DQoxLzEzICogMTYvNTENCmBgYA0KDQpTbywgdGhlIHByb2JhYmlsaXR5IG9mIEEgYW5kIEIgYW5kIEMgaXMgZXF1YWwgdG8gdGhlIHByb2JhYmlsaXR5IG9mIEEgdGltZXMgdGhlIHByb2JhYmlsaXR5IG9mIEIgZ2l2ZW4gdGhhdCBBIGhhcHBlbmVkIHRpbWVzIHRoZSBwcm9iYWJpbGl0eSBvZiBDIGdpdmVuIHRoYXQgQSBhbmQgQiBoYXBwZW5lZA0KDQpgUHIoQSBhbmQgQiBhbmQgQykgPSBQcihBKSpQcihCfEEpKlByKEN8QSBhbmQgQilgDQoNCk9uZSBiYWxsIHdpbGwgYmUgZHJhd24gYXQgcmFuZG9tIGZyb20gYSBib3ggY29udGFpbmluZzogMyBjeWFuIGJhbGxzLCA1IG1hZ2VudGEgYmFsbHMsIGFuZCA3IHllbGxvdyBiYWxscy4NCg0KYGBge3J9DQpib3ggPC0gcmVwKCBjKCdjeWFuJywgJ21hZ2VudGEnLCAneWVsbG93JyksIHRpbWVzID0gYygzLDUsNykpDQpib3gNCmBgYA0KDQpJbnN0ZWFkIG9mIHRha2luZyBqdXN0IG9uZSBkcmF3LCBjb25zaWRlciB0YWtpbmcgdHdvIGRyYXdzLiBZb3UgdGFrZSB0aGUgc2Vjb25kIGRyYXcgd2l0aG91dCByZXR1cm5pbmcgdGhlIGZpcnN0IGRyYXcgdG8gdGhlIGJveC4gV2UgY2FsbCB0aGlzIHNhbXBsaW5nIHdpdGhvdXQgcmVwbGFjZW1lbnQuDQoNCmBgYHtyfQ0KMy8xNSAqIDEyLzE0DQpgYGANCk5vdyByZXBlYXQgdGhlIGV4cGVyaW1lbnQsIGJ1dCB0aGlzIHRpbWUsIGFmdGVyIHRha2luZyB0aGUgZmlyc3QgZHJhdyBhbmQgcmVjb3JkaW5nIHRoZSBjb2xvciwgcmV0dXJuIGl0IGJhY2sgdG8gdGhlIGJveCBhbmQgc2hha2UgdGhlIGJveC4gV2UgY2FsbCB0aGlzIHNhbXBsaW5nIHdpdGggcmVwbGFjZW1lbnQuDQoNCldoYXQgaXMgdGhlIHByb2JhYmlsaXR5IHRoYXQgdGhlIGZpcnN0IGRyYXcgaXMgY3lhbiBhbmQgdGhhdCB0aGUgc2Vjb25kIGRyYXcgaXMgbm90IGN5YW4/DQoNCmBgYHtyfQ0KMy8xNSAqIDEyLzE1DQpgYGANCg0KIyBDb21iaW5hdGlvbnMgYW5kIFBlcm11dGF0aW9ucw0KDQpgYGB7cn0NCiMgam9pbmluZyBzdHJpbmdzIHdpdGggcGFzdGUNCm51bWJlciA8LSAiVGhyZWUiDQpzdWl0IDwtICJIZWFydHMiDQpwYXN0ZShudW1iZXIsIHN1aXQpDQoNCiMgam9pbmluZyB2ZWN0b3JzIGVsZW1lbnQtd2lzZSB3aXRoIHBhc3RlDQpwYXN0ZShsZXR0ZXJzWzE6NV0sIGFzLmNoYXJhY3RlcigxOjUpKQ0KYGBgDQoNClRoZSBmdW5jdGlvbiBgZXhwbGFuZC5ncmlkKClgIGdpdmVzIHVzIGFsbCBjb21iaW5hdGlvbnMgb2YgMiBsaXN0cy4NCg0KYGBge3J9DQpleHBhbmQuZ3JpZChwYW50cyA9IGMoImJsdWUiLCAiYmxhY2siKSwgc2hpcnQgPSBjKCJ3aGl0ZSIsICJncmV5IiwgInBsYWlkIikpDQpgYGANCg0KVG8gZ2VuZXJhdGUgYSBkZWNrIG9mIGNhcmRzOg0KDQpgYGB7cn0NCnN1aXRzIDwtIGMoIkRpYW1vbmRzIiwgIkNsdWJzIiwgIkhlYXJ0cyIsICJTcGFkZXMiKQ0KbnVtYmVycyA8LSBjKCJBY2UiLCAiRGV1Y2UiLCAiVGhyZWUiLCAiRm91ciIsICJGaXZlIiwgIlNpeCIsICJTZXZlbiIsICJFaWdodCIsICJOaW5lIiwgIlRlbiIsICJKYWNrIiwgIlF1ZWVuIiwgIktpbmciKQ0KZGVjayA8LSBleHBhbmQuZ3JpZChudW1iZXIgPSBudW1iZXJzLCBzdWl0ID0gc3VpdHMpDQpkZWNrIDwtIHBhc3RlKGRlY2skbnVtYmVyLCBkZWNrJHN1aXQpDQpgYGANCg0KVG8gZmluZCB0aGUgcHJvYmFiaWxpdHkgb2YgZHJhd2luZyBhIGtpbmc6DQoNCmBgYHtyfQ0Ka2luZ3MgPC0gcGFzdGUoIktpbmciLCBzdWl0cykNCm1lYW4oZGVjayAlaW4lIGtpbmdzKQ0KYGBgDQpXaGF0IGlzIHRoZSBjb25kaXRpb25hbCBwcm9iYWJpbGl0eSBvZiB0aGUgc2Vjb25kIGNhcmQgaXMgYSBraW5nPw0KDQpUaGUgYHBlcm11dGF0aW9ucygpYCBmdW5jdGlvbiBjb21wdXRlcywgZm9yIGFueSBsaXN0IG9mIHNpemUgJ24nIGFsbCB0aGUgZGlmZmVyZW50IHdheXMgd2UgY2FuIHNlbGVjdCAncicgaXRlbXMuDQpgYGB7cn0NCmxpYnJhcnkoZ3Rvb2xzKQ0KIyBUaGlzIHdpbGwgY2FsY3VsYXRlIGFsbCB0aGUgd2F5cyB5b3UgY2FuIGNob29zZSAyIG51bWJlcnMgZnJvbSBhIGxpc3Qgb2YgMS01Lg0KcGVybXV0YXRpb25zKDUsMikNCmBgYA0KDQpUbyBjb21wdXRlIGFsbCB0aGUgcG9zc2libGUgd2F5cyB0aGF0IHlvdSBjYW4gY2hvb3NlIDIgY2FyZHMgKndoZW4gdGhlIG9yZGVyIG1hdHRlcnMqIHdlIGNhbiB0eXBlOg0KDQpgYGB7cn0NCiMgV2UgaGF2ZSA1MiBjYXJkcywgd2Ugd2lsbCBjaG9vc2UgMiwgYW5kIHdlIHdpbGwgc2VsZWN0IHRoZW0gZnJvbSB0aGUgdmVjdG9yIG9mIG91ciBjYXJkIG5hbWVzDQpoYW5kcyA8LSBwZXJtdXRhdGlvbnMoNTIsMiwgdiA9IGRlY2spDQoNCmZpcnN0X2NhcmQgPC0gaGFuZHNbLDFdDQoNCnNlY29uZF9jYXJkIDwtIGhhbmRzWywyXQ0KIyBIb3cgbWFueSBjYXNlcyBpcyB0aGUgZmlyc3QgY2FyZCBhIGtpbmc/DQpzdW0oZmlyc3RfY2FyZCAlaW4lIGtpbmdzKQ0KIyBXZSBhc2sgaG93IHdoYXQgZnJhY3Rpb24gb2YgdGhlc2UgMjA0IGFsc28gaGF2ZSBhIGtpbmcgaW4gdGhlIHNlY29uZCBjYXJkPw0Kc3VtKGZpcnN0X2NhcmQgJWluJSBraW5ncyAmIHNlY29uZF9jYXJkICVpbiUga2luZ3MpIC8gc3VtKGZpcnN0X2NhcmQgJWluJSBraW5ncykNCmBgYA0KDQpXaGF0IGlmIHRoZSAqKm9yZGVyIGRvZXMgbm90IG1hdHRlcioqPyBVc2UgdGhlIGBjb21iaW5hdGlvbnMoKWAgZnVuY3Rpb24gc2luY2UgdGhlIG9yZGVyIGRvZXNuJ3QgbWF0dGVyLg0KDQpDb21wYXJlIHRoZSB0d28gZnVuY3Rpb25zDQoNCmBgYHtyfQ0KcGVybXV0YXRpb25zKDMsMikNCmNvbWJpbmF0aW9ucygzLDIpDQpgYGANCkRlZmluZSBhIHZlY3RvciB0aGF0IGluY2x1ZGVzIGFsbCB0aGUgYWNlcywgYXZlY3RvciB0aGF0IGluY2x1ZGVzIGFsbCB0aGUgZmFjZSBjYXJkcyBhbmQgMTAncywgdGhlbiBnZW5lcmF0ZSBhbGwgdGhlIGNvbWJpbmF0aW9ucyBvZiBwaWNraW5nIDIgY2FyZHMgb3V0IG9mIDUyLg0KDQpgYGB7cn0NCmFjZXMgPC0gcGFzdGUoIkFjZSIsIHN1aXRzKQ0KZmFjZWNhcmQgPC0gYygiS2luZyIsICJRdWVlbiIsICJKYWNrIiwgIlRlbiIpDQpmYWNlY2FyZCA8LSBleHBhbmQuZ3JpZChudW1iZXIgPSBmYWNlY2FyZCwgc3VpdCA9IHN1aXRzKQ0KZmFjZWNhcmQgPC0gcGFzdGUoZmFjZWNhcmQkbnVtYmVyLCBmYWNlY2FyZCRzdWl0KQ0KDQpoYW5kcyA8LSBjb21iaW5hdGlvbnMoNTIsIDIsIHY9ZGVjaykgIyBhbGwgcG9zc2libGUgaGFuZHMNCiMgcHJvYmFiaWxpdHkgb2YgYSBuYXR1cmFsIDIxIGdpdmVuIHRoYXQgdGhlIGFjZSBpcyBsaXN0ZWQgZmlyc3QgaW4gYGNvbWJpbmF0aW9uc2ANCm1lYW4oaGFuZHNbLDFdICVpbiUgYWNlcyAmIGhhbmRzWywyXSAlaW4lIGZhY2VjYXJkKQ0KYGBgDQoNCllvdSBjYW4gYWxzbyB1c2UgYSBNb250ZSBDYXJsbyBzaW11bGF0aW9uIHRvIGNhbGN1bGF0ZSB0aGUgcHJvYmFiaWxpdHkgb2YgZ2V0dGluZyBibGFja2phY2sgb24gdGhlIGZpcnN0IDIgY2FyZHMuDQoNClVzZSB0aGUgYHNhbXBsZSgpYCBmdW5jdGlvbiB0byBkcmF3IGNhcmRzIHdpdGhvdXQgcmVwbGFjZW1lbnQNCmBgYHtyfQ0KaGFuZCA8LSBzYW1wbGUoZGVjaywgMikNCmhhbmQNCmBgYA0KYGBge3J9DQojIGNvZGUgZm9yIEI9MTAsMDAwIGhhbmRzIG9mIGJsYWNramFjaw0KQiA8LSAxMDAwMA0KcmVzdWx0cyA8LSByZXBsaWNhdGUoQiwgew0KICAgIGhhbmQgPC0gc2FtcGxlKGRlY2ssIDIpDQogICAgKGhhbmRbMV0gJWluJSBhY2VzICYgaGFuZFsyXSAlaW4lIGZhY2VjYXJkKSB8IChoYW5kWzJdICVpbiUgYWNlcyAmIGhhbmRbMV0gJWluJSBmYWNlY2FyZCkNCn0pDQptZWFuKHJlc3VsdHMpDQpgYGANCg0KIyMgVGhlIGJpcnRoZGF5IHByb2JsZW0NCg0KSWYgeW91IGFyZSBpbiBhIGNsYXNzcm9vbSB3aXRoIDUwIHBlb3BsZSwgYXNzdW1pbmcgaXQgaXMgYSByYW5kb21seSBzZWxlY3RlZCBncm91cCwgd2hhdCBpcyB0aGUgY2hhbmNlIHRoYXQgYXQgbGVhc3QgMiBwZW9wbGUgaGF2ZSB0aGUgc2FtZSBiaXJ0aGRheT8NCg0KV2Ugd2lsbCBjYWxjdWxhdGUgdGhpcyBsYXRlciwgYnV0IGZpcnN0IHdlIGNhbiB1c2UgdGhlIE1vbnRlIENhcmxvIHNpbXVsYXRpb24uDQoNCmBgYHtyfQ0KbiA8LSA1MA0KY2FsZW5kYXIgPC0gMTozNjUNCmJkYXlzIDwtIHNhbXBsZShjYWxlbmRhciwgbiwgcmVwbGFjZT1UUlVFKQ0KYGBgDQoNClRvIGNoZWNrIHRvIHNlZSBpZiB0d28gcGVvcGxlIGhhdmUgdGhlIHNhbWUgYmlydGhkYXksIHVzZSB0aGUgZnVuY3Rpb24gYGR1cGxpY2F0ZWQoKWAgd2hpY2ggcmV0dXJucyAqVFJVRSogaWYgYW55IGVsZW1lbnQgb2YgYSB2ZWN0b3IgaGFzIGFscmVhZHkgYXBwZWFyZWQgaW4gdGhhdCB2ZWN0b3IuDQoNCmBgYHtyfQ0KYW55KGR1cGxpY2F0ZWQoYmRheXMpKQ0KYGBgDQoNCmBgYHtyfQ0KYiA8LSAxMDAwMA0KcmVzdWx0cyA8LSByZXBsaWNhdGUoQix7DQogIGJkYXlzIDwtIHNhbXBsZShjYWxlbmRhciwgbiwgcmVwbGFjZT1UUlVFKQ0KICBhbnkoZHVwbGljYXRlZChiZGF5cykpDQp9KQ0KYGBgDQoNClRha2UgdGhlIG1lYW4gdG8gZGV0ZXJtaW5lIGhvdyBsaWtlbHkgaXQgaXMgZm9yIHR3byBwZW9wbGUgdG8gaGF2ZSB0aGUgc2FtZSBiaXJ0aGRheQ0KYGBge3J9DQptZWFuKHJlc3VsdHMpDQpgYGANCg0KIyBzYXBwbHkNCg0KYHNhcHBseSgpYCBhbGxvd3MgdXMgdG8gcGVyZm9ybSBlbGVtZW50LXdpc2Ugb3BlcmF0aW9ucyBvbiBhbnkgZnVuY3Rpb24uIA0KDQpUaGlzIHdpbGwgYXBwbHkgc3F1YXJlIHJvb3QgdG8gZWFjaCBlbGVtZW50IG9mIHguIFlvdSBhY3R1YWxseSBkb24ndCBuZWVkIHRvIGRvIHRoaXMgYmVjYXVzZSBgc3FydCgpYCBhbHJlYWR5IG9wZXJhdGVzIG9uIGEgdmVjdG9yIGVsZW1lbnQgYnkgZWxlbWVudCwgYnV0IHNvbWUgZnVuY3Rpb25zIGRvIG5vdC4NCg0KYGBge3J9DQp4IDwtIDE6MTANCnNhcHBseSh4LCBzcXJ0KQ0KYGBgDQoNCklmIHlvdSB3YW50ZWQgdG8gYmV0IG9uIHRoZSBjaGFuY2VzIHRoYXQgMiBwZW9wbGUgaGF2ZSB0aGUgc2FtZSBiaXJ0aGRheSBpbiBhIGdyb3VwIG9mIHBlb3BsZSwgeW91IGNhbiB1c2UgYSBNb250ZSBDYXJsbyBzaW11bGF0aW9uLiBXZSB3aWxsIGRlZmluZSBhIGZ1bmN0aW9uIHRvIGNhY2x1YXRlIHRoZSBwcm9iYWJpbGl0eSBvZiBzaGFyZWQgYmRheXMgYWNyb3NzIG4gcGVvcGxlLg0KDQpgYGB7ciBjYWNoZT1UUlVFfQ0KY29tcHV0ZV9wcm9iIDwtIGZ1bmN0aW9uKG4sIEIgPSAxMDAwMCkgew0KCXNhbWVfZGF5IDwtIHJlcGxpY2F0ZShCLCB7DQogICAgCWJkYXlzIDwtIHNhbXBsZSgxOjM2NSwgbiwgcmVwbGFjZSA9IFRSVUUpDQogICAgICAgIGFueShkdXBsaWNhdGVkKGJkYXlzKSkNCiAgICB9KQ0KICAgIG1lYW4oc2FtZV9kYXkpDQp9DQoNCm4gPC0gc2VxKDEsIDYwKQ0KcHJvYiA8LSBzYXBwbHkobiwgY29tcHV0ZV9wcm9iKQ0KYGBgDQoNCg0KYGBge3J9DQpwbG90KG4sIHByb2IpDQpgYGANCg0KSWYgd2Ugd2FudGVkIHRvIGNvbXB1dGUgdGhlIGV4YWN0IHZhbHVlIGluc3RlYWQgb2YgdXNpbmcgYSBNb250ZSBDYXJsbyBTaW11bGF0aW9uIHdlIGNhbiBjYWxjdWxhdGUgdGhlIGV4YWN0IHZhbHVlLiBJbnN0ZWFkIG9mIGNhbGN1bGF0aW5nIHRoZSBwcm9iYWJpbGl0eSBvZiBpdCBoYXBwZW5pbmcsIGl0IGlzIGZhc3RlciB0byBjYWxjdWxhdGUgdGhlIHByb2JhYmlsaXR5IG9mIGl0IG5vdCBoYXBwZW5pbmcgdGhlbiB1c2UgdGhlIG11bHRpcGxpY2F0aW9uIHJ1bGUuDQoNClN0YXJ0aW5nIHdpdGggcGVyc29uIDEsIHRoZSBwcm9iYWJpbGl0eSB0aGF0IHRoZXkgaGF2ZSBhIHVuaXF1ZSBiaXJ0aGRheSBpcyAxLg0KDQpXZSBjYW4gY29tcHV0ZSB0aGUgcHJvYmFiaWxpdHkgb2Ygc2hhcmVkIGJpcnRoZGF5cyBtYXRoZW1hdGljYWxseToNCg0KPG1hdGggeG1sbnM9Imh0dHA6Ly93d3cudzMub3JnLzE5OTgvTWF0aC9NYXRoTUwiPg0KICA8bWFjdGlvbiBpZD0iTUpYLUNvbGxhcHNlLTkiIGFjdGlvbnR5cGU9InRvZ2dsZSIgc2VsZWN0aW9uPSIyIiBkYXRhLXNlbWFudGljLWNvbXBsZXhpdHk9IjMiPg0KICAgIDxtdGV4dCBkYXRhLXNlbWFudGljLWNvbXBsZXhpdHk9IjMiPiYjeDI1QzI7Li4uJiN4MjVCODs8L210ZXh0Pg0KICAgIDxtcm93IGRhdGEtc2VtYW50aWMtY29tcGxleGl0eT0iMjAiIGRhdGEtc2VtYW50aWMtY29sbGFwc2VkPSIoNDcgKGMgNDQgNDUgNDYpIDAgNDAgNCA0MykiIGRhdGEtc2VtYW50aWMtY2hpbGRyZW49IjAsNDAsNCw0MyIgZGF0YS1zZW1hbnRpYy1pZD0iNDciIGRhdGEtc2VtYW50aWMtcm9sZT0idGV4dCIgZGF0YS1zZW1hbnRpYy10eXBlPSJwdW5jdHVhdGVkIj4NCiAgICAgIDxtcm93Pg0KICAgICAgICA8bXN0eWxlIGRpc3BsYXlzdHlsZT0iZmFsc2UiIHNjcmlwdGxldmVsPSIwIiBkYXRhLXNlbWFudGljLWNvbXBsZXhpdHk9IjMiPg0KICAgICAgICAgIDxtYWN0aW9uIGlkPSJNSlgtQ29sbGFwc2UtMiIgYWN0aW9udHlwZT0idG9nZ2xlIiBzZWxlY3Rpb249IjIiIGRhdGEtc2VtYW50aWMtY29tcGxleGl0eT0iMyI+DQogICAgICAgICAgICA8bXRleHQgZGF0YS1zZW1hbnRpYy1jb21wbGV4aXR5PSIzIj4mI3gyNUMyOy4uLiYjeDI1Qjg7PC9tdGV4dD4NCiAgICAgICAgICAgIDxtdGV4dCBkYXRhLXNlbWFudGljLXR5cGU9InRleHQiIGRhdGEtc2VtYW50aWMtcm9sZT0idW5rbm93biIgZGF0YS1zZW1hbnRpYy1mb250PSJub3JtYWwiIGRhdGEtc2VtYW50aWMtaWQ9IjAiIGRhdGEtc2VtYW50aWMtcGFyZW50PSI0NyIgZGF0YS1zZW1hbnRpYy1jb21wbGV4aXR5PSIxMC41Ij5QcihzaGFyZWQgYmlydGhkYXlzKTwvbXRleHQ+DQogICAgICAgICAgPC9tYWN0aW9uPg0KICAgICAgICA8L21zdHlsZT4NCiAgICAgICAgPG1yb3cgZGF0YS1zZW1hbnRpYy10eXBlPSJyZWxzZXEiIGRhdGEtc2VtYW50aWMtcm9sZT0iZXF1YWxpdHkiIGRhdGEtc2VtYW50aWMtaWQ9IjQwIiBkYXRhLXNlbWFudGljLWNoaWxkcmVuPSIzOCwzOSIgZGF0YS1zZW1hbnRpYy1jb250ZW50PSIxIiBkYXRhLXNlbWFudGljLXBhcmVudD0iNDciIGRhdGEtc2VtYW50aWMtY29tcGxleGl0eT0iOCI+DQogICAgICAgICAgPG1yb3cgZGF0YS1zZW1hbnRpYy10eXBlPSJlbXB0eSIgZGF0YS1zZW1hbnRpYy1yb2xlPSJ1bmtub3duIiBkYXRhLXNlbWFudGljLWlkPSIzOCIgZGF0YS1zZW1hbnRpYy1wYXJlbnQ9IjQwIiBkYXRhLXNlbWFudGljLWNvbXBsZXhpdHk9IjAiIC8+DQogICAgICAgICAgPG1vIGRhdGEtc2VtYW50aWMtdHlwZT0icmVsYXRpb24iIGRhdGEtc2VtYW50aWMtcm9sZT0iZXF1YWxpdHkiIGRhdGEtc2VtYW50aWMtaWQ9IjEiIGRhdGEtc2VtYW50aWMtcGFyZW50PSI0MCIgZGF0YS1zZW1hbnRpYy1vcGVyYXRvcj0icmVsc2VxLD0iIGRhdGEtc2VtYW50aWMtY29tcGxleGl0eT0iMSI+PTwvbW8+DQogICAgICAgICAgPG1yb3cgZGF0YS1zZW1hbnRpYy10eXBlPSJwb3N0Zml4b3AiIGRhdGEtc2VtYW50aWMtcm9sZT0ic3VidHJhY3Rpb24iIGRhdGEtc2VtYW50aWMtaWQ9IjM5IiBkYXRhLXNlbWFudGljLWNoaWxkcmVuPSIyIiBkYXRhLXNlbWFudGljLWNvbnRlbnQ9IjMiIGRhdGEtc2VtYW50aWMtcGFyZW50PSI0MCIgZGF0YS1zZW1hbnRpYy1jb21wbGV4aXR5PSI0Ij4NCiAgICAgICAgICAgIDxtbiBkYXRhLXNlbWFudGljLXR5cGU9Im51bWJlciIgZGF0YS1zZW1hbnRpYy1yb2xlPSJpbnRlZ2VyIiBkYXRhLXNlbWFudGljLWZvbnQ9Im5vcm1hbCIgZGF0YS1zZW1hbnRpYy1pZD0iMiIgZGF0YS1zZW1hbnRpYy1wYXJlbnQ9IjM5IiBkYXRhLXNlbWFudGljLWNvbXBsZXhpdHk9IjEiPjE8L21uPg0KICAgICAgICAgICAgPG1vIGRhdGEtc2VtYW50aWMtdHlwZT0ib3BlcmF0b3IiIGRhdGEtc2VtYW50aWMtcm9sZT0ic3VidHJhY3Rpb24iIGRhdGEtc2VtYW50aWMtaWQ9IjMiIGRhdGEtc2VtYW50aWMtcGFyZW50PSIzOSIgZGF0YS1zZW1hbnRpYy1vcGVyYXRvcj0icG9zdGZpeG9wLCYjeDIyMTI7IiBkYXRhLXNlbWFudGljLWNvbXBsZXhpdHk9IjEiPiYjeDIyMTI7PC9tbz4NCiAgICAgICAgICA8L21yb3c+DQogICAgICAgIDwvbXJvdz4NCiAgICAgICAgPG1zdHlsZSBkaXNwbGF5c3R5bGU9ImZhbHNlIiBzY3JpcHRsZXZlbD0iMCIgZGF0YS1zZW1hbnRpYy1jb21wbGV4aXR5PSIzIj4NCiAgICAgICAgICA8bWFjdGlvbiBpZD0iTUpYLUNvbGxhcHNlLTMiIGFjdGlvbnR5cGU9InRvZ2dsZSIgc2VsZWN0aW9uPSIyIiBkYXRhLXNlbWFudGljLWNvbXBsZXhpdHk9IjMiPg0KICAgICAgICAgICAgPG10ZXh0IGRhdGEtc2VtYW50aWMtY29tcGxleGl0eT0iMyI+JiN4MjVDMjsuLi4mI3gyNUI4OzwvbXRleHQ+DQogICAgICAgICAgICA8bXRleHQgZGF0YS1zZW1hbnRpYy10eXBlPSJ0ZXh0IiBkYXRhLXNlbWFudGljLXJvbGU9InVua25vd24iIGRhdGEtc2VtYW50aWMtZm9udD0ibm9ybWFsIiBkYXRhLXNlbWFudGljLWlkPSI0IiBkYXRhLXNlbWFudGljLXBhcmVudD0iNDciIGRhdGEtc2VtYW50aWMtY29tcGxleGl0eT0iMTIiPlByKG5vIHNoYXJlZCBiaXJ0aGRheXMpPC9tdGV4dD4NCiAgICAgICAgICA8L21hY3Rpb24+DQogICAgICAgIDwvbXN0eWxlPg0KICAgICAgICA8bWFjdGlvbiBpZD0iTUpYLUNvbGxhcHNlLTgiIGFjdGlvbnR5cGU9InRvZ2dsZSIgc2VsZWN0aW9uPSIyIiBkYXRhLXNlbWFudGljLWNvbXBsZXhpdHk9IjIiPg0KICAgICAgICAgIDxtdGV4dCBkYXRhLXNlbWFudGljLWNvbXBsZXhpdHk9IjIiPiYjeDI1QzI7PSYjeDI1Qjg7PC9tdGV4dD4NCiAgICAgICAgICA8bXJvdyBkYXRhLXNlbWFudGljLXR5cGU9InJlbHNlcSIgZGF0YS1zZW1hbnRpYy1yb2xlPSJlcXVhbGl0eSIgZGF0YS1zZW1hbnRpYy1pZD0iNDMiIGRhdGEtc2VtYW50aWMtY2hpbGRyZW49IjQxLDQyIiBkYXRhLXNlbWFudGljLWNvbnRlbnQ9IjUiIGRhdGEtc2VtYW50aWMtcGFyZW50PSI0NyIgZGF0YS1zZW1hbnRpYy1jb21wbGV4aXR5PSIxNiI+DQogICAgICAgICAgICA8bXJvdyBkYXRhLXNlbWFudGljLXR5cGU9ImVtcHR5IiBkYXRhLXNlbWFudGljLXJvbGU9InVua25vd24iIGRhdGEtc2VtYW50aWMtaWQ9IjQxIiBkYXRhLXNlbWFudGljLXBhcmVudD0iNDMiIGRhdGEtc2VtYW50aWMtY29tcGxleGl0eT0iMCIgLz4NCiAgICAgICAgICAgIDxtbyBkYXRhLXNlbWFudGljLXR5cGU9InJlbGF0aW9uIiBkYXRhLXNlbWFudGljLXJvbGU9ImVxdWFsaXR5IiBkYXRhLXNlbWFudGljLWlkPSI1IiBkYXRhLXNlbWFudGljLXBhcmVudD0iNDMiIGRhdGEtc2VtYW50aWMtb3BlcmF0b3I9InJlbHNlcSw9IiBkYXRhLXNlbWFudGljLWNvbXBsZXhpdHk9IjEiPj08L21vPg0KICAgICAgICAgICAgPG1yb3cgZGF0YS1zZW1hbnRpYy10eXBlPSJpbmZpeG9wIiBkYXRhLXNlbWFudGljLXJvbGU9InN1YnRyYWN0aW9uIiBkYXRhLXNlbWFudGljLWlkPSI0MiIgZGF0YS1zZW1hbnRpYy1jaGlsZHJlbj0iNiwzNyIgZGF0YS1zZW1hbnRpYy1jb250ZW50PSI3IiBkYXRhLXNlbWFudGljLXBhcmVudD0iNDMiIGRhdGEtc2VtYW50aWMtY29tcGxleGl0eT0iMTIiPg0KICAgICAgICAgICAgICA8bW4gZGF0YS1zZW1hbnRpYy10eXBlPSJudW1iZXIiIGRhdGEtc2VtYW50aWMtcm9sZT0iaW50ZWdlciIgZGF0YS1zZW1hbnRpYy1mb250PSJub3JtYWwiIGRhdGEtc2VtYW50aWMtaWQ9IjYiIGRhdGEtc2VtYW50aWMtcGFyZW50PSI0MiIgZGF0YS1zZW1hbnRpYy1jb21wbGV4aXR5PSIxIj4xPC9tbj4NCiAgICAgICAgICAgICAgPG1vIGRhdGEtc2VtYW50aWMtdHlwZT0ib3BlcmF0b3IiIGRhdGEtc2VtYW50aWMtcm9sZT0ic3VidHJhY3Rpb24iIGRhdGEtc2VtYW50aWMtaWQ9IjciIGRhdGEtc2VtYW50aWMtcGFyZW50PSI0MiIgZGF0YS1zZW1hbnRpYy1vcGVyYXRvcj0iaW5maXhvcCwmI3gyMjEyOyIgZGF0YS1zZW1hbnRpYy1jb21wbGV4aXR5PSIxIj4mI3gyMjEyOzwvbW8+DQogICAgICAgICAgICAgIDxtcm93IGRhdGEtc2VtYW50aWMtdHlwZT0iZmVuY2VkIiBkYXRhLXNlbWFudGljLXJvbGU9ImxlZnRyaWdodCIgZGF0YS1zZW1hbnRpYy1pZD0iMzciIGRhdGEtc2VtYW50aWMtY2hpbGRyZW49IjM2IiBkYXRhLXNlbWFudGljLWNvbnRlbnQ9IjgsMzIiIGRhdGEtc2VtYW50aWMtcGFyZW50PSI0MiIgZGF0YS1zZW1hbnRpYy1jb21wbGV4aXR5PSI3Ij4NCiAgICAgICAgICAgICAgICA8bW8gc3RyZXRjaHk9ImZhbHNlIiBkYXRhLXNlbWFudGljLXR5cGU9ImZlbmNlIiBkYXRhLXNlbWFudGljLXJvbGU9Im9wZW4iIGRhdGEtc2VtYW50aWMtaWQ9IjgiIGRhdGEtc2VtYW50aWMtcGFyZW50PSIzNyIgZGF0YS1zZW1hbnRpYy1vcGVyYXRvcj0iZmVuY2VkIiBkYXRhLXNlbWFudGljLWNvbXBsZXhpdHk9IjEiPig8L21vPg0KICAgICAgICAgICAgICAgIDxtYWN0aW9uIGlkPSJNSlgtQ29sbGFwc2UtNyIgYWN0aW9udHlwZT0idG9nZ2xlIiBzZWxlY3Rpb249IjIiIGRhdGEtc2VtYW50aWMtY29tcGxleGl0eT0iMiI+DQogICAgICAgICAgICAgICAgICA8bXRleHQgZGF0YS1zZW1hbnRpYy1jb21wbGV4aXR5PSIyIj4mI3gyNUMyOywmI3gyNUI4OzwvbXRleHQ+DQogICAgICAgICAgICAgICAgICA8bXJvdyBkYXRhLXNlbWFudGljLXR5cGU9InB1bmN0dWF0ZWQiIGRhdGEtc2VtYW50aWMtcm9sZT0ic2VxdWVuY2UiIGRhdGEtc2VtYW50aWMtaWQ9IjM2IiBkYXRhLXNlbWFudGljLWNoaWxkcmVuPSIzMywxOSwyMCwyMSwzNSIgZGF0YS1zZW1hbnRpYy1jb250ZW50PSIxOSwyMCwyMSIgZGF0YS1zZW1hbnRpYy1wYXJlbnQ9IjM3IiBkYXRhLXNlbWFudGljLWNvbXBsZXhpdHk9IjE1Ij4NCiAgICAgICAgICAgICAgICAgICAgPG1hY3Rpb24gaWQ9Ik1KWC1Db2xsYXBzZS00IiBhY3Rpb250eXBlPSJ0b2dnbGUiIHNlbGVjdGlvbj0iMiIgZGF0YS1zZW1hbnRpYy1jb21wbGV4aXR5PSIyIj4NCiAgICAgICAgICAgICAgICAgICAgICA8bXRleHQgZGF0YS1zZW1hbnRpYy1jb21wbGV4aXR5PSIyIj4mI3gyNUMyOysmI3gyNUI4OzwvbXRleHQ+DQogICAgICAgICAgICAgICAgICAgICAgPG1yb3cgZGF0YS1zZW1hbnRpYy10eXBlPSJpbmZpeG9wIiBkYXRhLXNlbWFudGljLXJvbGU9InVua25vd24iIGRhdGEtc2VtYW50aWMtaWQ9IjMzIiBkYXRhLXNlbWFudGljLWNoaWxkcmVuPSI5LDEzLDM0IiBkYXRhLXNlbWFudGljLWNvbnRlbnQ9IjEwLDE0IiBkYXRhLXNlbWFudGljLXBhcmVudD0iMzYiIGRhdGEtc2VtYW50aWMtY29tcGxleGl0eT0iMjQuNiI+DQogICAgICAgICAgICAgICAgICAgICAgICA8bW4gZGF0YS1zZW1hbnRpYy10eXBlPSJudW1iZXIiIGRhdGEtc2VtYW50aWMtcm9sZT0iaW50ZWdlciIgZGF0YS1zZW1hbnRpYy1mb250PSJub3JtYWwiIGRhdGEtc2VtYW50aWMtaWQ9IjkiIGRhdGEtc2VtYW50aWMtcGFyZW50PSIzMyIgZGF0YS1zZW1hbnRpYy1jb21wbGV4aXR5PSIxIj4xPC9tbj4NCiAgICAgICAgICAgICAgICAgICAgICAgIDxtbyBkYXRhLXNlbWFudGljLXR5cGU9Im9wZXJhdG9yIiBkYXRhLXNlbWFudGljLXJvbGU9InVua25vd24iIGRhdGEtc2VtYW50aWMtaWQ9IjEwIiBkYXRhLXNlbWFudGljLXBhcmVudD0iMzMiIGRhdGEtc2VtYW50aWMtb3BlcmF0b3I9ImluZml4b3AsJiN4RDc7IiBkYXRhLXNlbWFudGljLWNvbXBsZXhpdHk9IjEiPiYjeEQ3OzwvbW8+DQogICAgICAgICAgICAgICAgICAgICAgICA8bWZyYWMgZGF0YS1zZW1hbnRpYy10eXBlPSJmcmFjdGlvbiIgZGF0YS1zZW1hbnRpYy1yb2xlPSJ2dWxnYXIiIGRhdGEtc2VtYW50aWMtaWQ9IjEzIiBkYXRhLXNlbWFudGljLWNoaWxkcmVuPSIxMSwxMiIgZGF0YS1zZW1hbnRpYy1wYXJlbnQ9IjMzIiBkYXRhLXNlbWFudGljLWNvbXBsZXhpdHk9IjYuODAwMDAwMDAwMDAwMDAxIj4NCiAgICAgICAgICAgICAgICAgICAgICAgICAgPG1uIGRhdGEtc2VtYW50aWMtdHlwZT0ibnVtYmVyIiBkYXRhLXNlbWFudGljLXJvbGU9ImludGVnZXIiIGRhdGEtc2VtYW50aWMtZm9udD0ibm9ybWFsIiBkYXRhLXNlbWFudGljLWlkPSIxMSIgZGF0YS1zZW1hbnRpYy1wYXJlbnQ9IjEzIiBkYXRhLXNlbWFudGljLWNvbXBsZXhpdHk9IjIiPjM2NDwvbW4+DQogICAgICAgICAgICAgICAgICAgICAgICAgIDxtbiBkYXRhLXNlbWFudGljLXR5cGU9Im51bWJlciIgZGF0YS1zZW1hbnRpYy1yb2xlPSJpbnRlZ2VyIiBkYXRhLXNlbWFudGljLWZvbnQ9Im5vcm1hbCIgZGF0YS1zZW1hbnRpYy1pZD0iMTIiIGRhdGEtc2VtYW50aWMtcGFyZW50PSIxMyIgZGF0YS1zZW1hbnRpYy1jb21wbGV4aXR5PSIyIj4zNjU8L21uPg0KICAgICAgICAgICAgICAgICAgICAgICAgPC9tZnJhYz4NCiAgICAgICAgICAgICAgICAgICAgICAgIDxtbyBkYXRhLXNlbWFudGljLXR5cGU9Im9wZXJhdG9yIiBkYXRhLXNlbWFudGljLXJvbGU9InVua25vd24iIGRhdGEtc2VtYW50aWMtaWQ9IjE0IiBkYXRhLXNlbWFudGljLXBhcmVudD0iMzMiIGRhdGEtc2VtYW50aWMtb3BlcmF0b3I9ImluZml4b3AsJiN4RDc7IiBkYXRhLXNlbWFudGljLWNvbXBsZXhpdHk9IjEiPiYjeEQ3OzwvbW8+DQogICAgICAgICAgICAgICAgICAgICAgICA8bXJvdyBkYXRhLXNlbWFudGljLXR5cGU9InBvc3RmaXhvcCIgZGF0YS1zZW1hbnRpYy1yb2xlPSJ1bmtub3duIiBkYXRhLXNlbWFudGljLWlkPSIzNCIgZGF0YS1zZW1hbnRpYy1jaGlsZHJlbj0iMTciIGRhdGEtc2VtYW50aWMtY29udGVudD0iMTgiIGRhdGEtc2VtYW50aWMtcGFyZW50PSIzMyIgZGF0YS1zZW1hbnRpYy1jb21wbGV4aXR5PSI5LjgiPg0KICAgICAgICAgICAgICAgICAgICAgICAgICA8bWZyYWMgZGF0YS1zZW1hbnRpYy10eXBlPSJmcmFjdGlvbiIgZGF0YS1zZW1hbnRpYy1yb2xlPSJ2dWxnYXIiIGRhdGEtc2VtYW50aWMtaWQ9IjE3IiBkYXRhLXNlbWFudGljLWNoaWxkcmVuPSIxNSwxNiIgZGF0YS1zZW1hbnRpYy1wYXJlbnQ9IjM0IiBkYXRhLXNlbWFudGljLWNvbXBsZXhpdHk9IjYuODAwMDAwMDAwMDAwMDAxIj4NCiAgICAgICAgICAgICAgICAgICAgICAgICAgICA8bW4gZGF0YS1zZW1hbnRpYy10eXBlPSJudW1iZXIiIGRhdGEtc2VtYW50aWMtcm9sZT0iaW50ZWdlciIgZGF0YS1zZW1hbnRpYy1mb250PSJub3JtYWwiIGRhdGEtc2VtYW50aWMtaWQ9IjE1IiBkYXRhLXNlbWFudGljLXBhcmVudD0iMTciIGRhdGEtc2VtYW50aWMtY29tcGxleGl0eT0iMiI+MzYzPC9tbj4NCiAgICAgICAgICAgICAgICAgICAgICAgICAgICA8bW4gZGF0YS1zZW1hbnRpYy10eXBlPSJudW1iZXIiIGRhdGEtc2VtYW50aWMtcm9sZT0iaW50ZWdlciIgZGF0YS1zZW1hbnRpYy1mb250PSJub3JtYWwiIGRhdGEtc2VtYW50aWMtaWQ9IjE2IiBkYXRhLXNlbWFudGljLXBhcmVudD0iMTciIGRhdGEtc2VtYW50aWMtY29tcGxleGl0eT0iMiI+MzY1PC9tbj4NCiAgICAgICAgICAgICAgICAgICAgICAgICAgPC9tZnJhYz4NCiAgICAgICAgICAgICAgICAgICAgICAgICAgPG1vIGRhdGEtc2VtYW50aWMtdHlwZT0ib3BlcmF0b3IiIGRhdGEtc2VtYW50aWMtcm9sZT0idW5rbm93biIgZGF0YS1zZW1hbnRpYy1pZD0iMTgiIGRhdGEtc2VtYW50aWMtcGFyZW50PSIzNCIgZGF0YS1zZW1hbnRpYy1vcGVyYXRvcj0icG9zdGZpeG9wLCYjeEQ3OyIgZGF0YS1zZW1hbnRpYy1jb21wbGV4aXR5PSIxIj4mI3hENzs8L21vPg0KICAgICAgICAgICAgICAgICAgICAgICAgPC9tcm93Pg0KICAgICAgICAgICAgICAgICAgICAgIDwvbXJvdz4NCiAgICAgICAgICAgICAgICAgICAgPC9tYWN0aW9uPg0KICAgICAgICAgICAgICAgICAgICA8bW8gZGF0YS1zZW1hbnRpYy10eXBlPSJwdW5jdHVhdGlvbiIgZGF0YS1zZW1hbnRpYy1yb2xlPSJmdWxsc3RvcCIgZGF0YS1zZW1hbnRpYy1pZD0iMTkiIGRhdGEtc2VtYW50aWMtcGFyZW50PSIzNiIgZGF0YS1zZW1hbnRpYy1vcGVyYXRvcj0icHVuY3R1YXRlZCIgZGF0YS1zZW1hbnRpYy1jb21wbGV4aXR5PSIxIj4uPC9tbz4NCiAgICAgICAgICAgICAgICAgICAgPG1vIGRhdGEtc2VtYW50aWMtdHlwZT0icHVuY3R1YXRpb24iIGRhdGEtc2VtYW50aWMtcm9sZT0iZnVsbHN0b3AiIGRhdGEtc2VtYW50aWMtaWQ9IjIwIiBkYXRhLXNlbWFudGljLXBhcmVudD0iMzYiIGRhdGEtc2VtYW50aWMtb3BlcmF0b3I9InB1bmN0dWF0ZWQiIGRhdGEtc2VtYW50aWMtY29tcGxleGl0eT0iMSI+LjwvbW8+DQogICAgICAgICAgICAgICAgICAgIDxtbyBkYXRhLXNlbWFudGljLXR5cGU9InB1bmN0dWF0aW9uIiBkYXRhLXNlbWFudGljLXJvbGU9ImZ1bGxzdG9wIiBkYXRhLXNlbWFudGljLWlkPSIyMSIgZGF0YS1zZW1hbnRpYy1wYXJlbnQ9IjM2IiBkYXRhLXNlbWFudGljLW9wZXJhdG9yPSJwdW5jdHVhdGVkIiBkYXRhLXNlbWFudGljLWNvbXBsZXhpdHk9IjEiPi48L21vPg0KICAgICAgICAgICAgICAgICAgICA8bXJvdyBkYXRhLXNlbWFudGljLXR5cGU9InByZWZpeG9wIiBkYXRhLXNlbWFudGljLXJvbGU9InVua25vd24iIGRhdGEtc2VtYW50aWMtaWQ9IjM1IiBkYXRhLXNlbWFudGljLWNoaWxkcmVuPSIzMSIgZGF0YS1zZW1hbnRpYy1jb250ZW50PSIyMiIgZGF0YS1zZW1hbnRpYy1wYXJlbnQ9IjM2IiBkYXRhLXNlbWFudGljLWNvbXBsZXhpdHk9IjUiPg0KICAgICAgICAgICAgICAgICAgICAgIDxtbyBkYXRhLXNlbWFudGljLXR5cGU9Im9wZXJhdG9yIiBkYXRhLXNlbWFudGljLXJvbGU9InVua25vd24iIGRhdGEtc2VtYW50aWMtaWQ9IjIyIiBkYXRhLXNlbWFudGljLXBhcmVudD0iMzUiIGRhdGEtc2VtYW50aWMtb3BlcmF0b3I9InByZWZpeG9wLCYjeEQ3OyIgZGF0YS1zZW1hbnRpYy1jb21wbGV4aXR5PSIxIj4mI3hENzs8L21vPg0KICAgICAgICAgICAgICAgICAgICAgIDxtYWN0aW9uIGlkPSJNSlgtQ29sbGFwc2UtNSIgYWN0aW9udHlwZT0idG9nZ2xlIiBzZWxlY3Rpb249IjIiIGRhdGEtc2VtYW50aWMtY29tcGxleGl0eT0iMiI+DQogICAgICAgICAgICAgICAgICAgICAgICA8bXRleHQgZGF0YS1zZW1hbnRpYy1jb21wbGV4aXR5PSIyIj4mI3gyNUMyOy8mI3gyNUI4OzwvbXRleHQ+DQogICAgICAgICAgICAgICAgICAgICAgICA8bWZyYWMgZGF0YS1zZW1hbnRpYy10eXBlPSJmcmFjdGlvbiIgZGF0YS1zZW1hbnRpYy1yb2xlPSJkaXZpc2lvbiIgZGF0YS1zZW1hbnRpYy1pZD0iMzEiIGRhdGEtc2VtYW50aWMtY2hpbGRyZW49IjI5LDMwIiBkYXRhLXNlbWFudGljLXBhcmVudD0iMzUiIGRhdGEtc2VtYW50aWMtY29tcGxleGl0eT0iMTQuOCI+DQogICAgICAgICAgICAgICAgICAgICAgICAgIDxtcm93IGRhdGEtc2VtYW50aWMtdHlwZT0iaW5maXhvcCIgZGF0YS1zZW1hbnRpYy1yb2xlPSJhZGRpdGlvbiIgZGF0YS1zZW1hbnRpYy1pZD0iMjkiIGRhdGEtc2VtYW50aWMtY2hpbGRyZW49IjI4LDI3IiBkYXRhLXNlbWFudGljLWNvbnRlbnQ9IjI2IiBkYXRhLXNlbWFudGljLXBhcmVudD0iMzEiIGRhdGEtc2VtYW50aWMtY29tcGxleGl0eT0iMTIiPg0KICAgICAgICAgICAgICAgICAgICAgICAgICAgIDxtcm93IGRhdGEtc2VtYW50aWMtdHlwZT0iaW5maXhvcCIgZGF0YS1zZW1hbnRpYy1yb2xlPSJzdWJ0cmFjdGlvbiIgZGF0YS1zZW1hbnRpYy1pZD0iMjgiIGRhdGEtc2VtYW50aWMtY2hpbGRyZW49IjIzLDI1IiBkYXRhLXNlbWFudGljLWNvbnRlbnQ9IjI0IiBkYXRhLXNlbWFudGljLXBhcmVudD0iMjkiIGRhdGEtc2VtYW50aWMtY29tcGxleGl0eT0iNyI+DQogICAgICAgICAgICAgICAgICAgICAgICAgICAgICA8bW4gZGF0YS1zZW1hbnRpYy10eXBlPSJudW1iZXIiIGRhdGEtc2VtYW50aWMtcm9sZT0iaW50ZWdlciIgZGF0YS1zZW1hbnRpYy1mb250PSJub3JtYWwiIGRhdGEtc2VtYW50aWMtaWQ9IjIzIiBkYXRhLXNlbWFudGljLXBhcmVudD0iMjgiIGRhdGEtc2VtYW50aWMtY29tcGxleGl0eT0iMiI+MzY1PC9tbj4NCiAgICAgICAgICAgICAgICAgICAgICAgICAgICAgIDxtbyBkYXRhLXNlbWFudGljLXR5cGU9Im9wZXJhdG9yIiBkYXRhLXNlbWFudGljLXJvbGU9InN1YnRyYWN0aW9uIiBkYXRhLXNlbWFudGljLWlkPSIyNCIgZGF0YS1zZW1hbnRpYy1wYXJlbnQ9IjI4IiBkYXRhLXNlbWFudGljLW9wZXJhdG9yPSJpbmZpeG9wLCYjeDIyMTI7IiBkYXRhLXNlbWFudGljLWNvbXBsZXhpdHk9IjEiPiYjeDIyMTI7PC9tbz4NCiAgICAgICAgICAgICAgICAgICAgICAgICAgICAgIDxtaSBkYXRhLXNlbWFudGljLXR5cGU9ImlkZW50aWZpZXIiIGRhdGEtc2VtYW50aWMtcm9sZT0ibGF0aW5sZXR0ZXIiIGRhdGEtc2VtYW50aWMtZm9udD0iaXRhbGljIiBkYXRhLXNlbWFudGljLWlkPSIyNSIgZGF0YS1zZW1hbnRpYy1wYXJlbnQ9IjI4IiBkYXRhLXNlbWFudGljLWNvbXBsZXhpdHk9IjEiPm48L21pPg0KICAgICAgICAgICAgICAgICAgICAgICAgICAgIDwvbXJvdz4NCiAgICAgICAgICAgICAgICAgICAgICAgICAgICA8bW8gZGF0YS1zZW1hbnRpYy10eXBlPSJvcGVyYXRvciIgZGF0YS1zZW1hbnRpYy1yb2xlPSJhZGRpdGlvbiIgZGF0YS1zZW1hbnRpYy1pZD0iMjYiIGRhdGEtc2VtYW50aWMtcGFyZW50PSIyOSIgZGF0YS1zZW1hbnRpYy1vcGVyYXRvcj0iaW5maXhvcCwrIiBkYXRhLXNlbWFudGljLWNvbXBsZXhpdHk9IjEiPis8L21vPg0KICAgICAgICAgICAgICAgICAgICAgICAgICAgIDxtbiBkYXRhLXNlbWFudGljLXR5cGU9Im51bWJlciIgZGF0YS1zZW1hbnRpYy1yb2xlPSJpbnRlZ2VyIiBkYXRhLXNlbWFudGljLWZvbnQ9Im5vcm1hbCIgZGF0YS1zZW1hbnRpYy1pZD0iMjciIGRhdGEtc2VtYW50aWMtcGFyZW50PSIyOSIgZGF0YS1zZW1hbnRpYy1jb21wbGV4aXR5PSIxIj4xPC9tbj4NCiAgICAgICAgICAgICAgICAgICAgICAgICAgPC9tcm93Pg0KICAgICAgICAgICAgICAgICAgICAgICAgICA8bW4gZGF0YS1zZW1hbnRpYy10eXBlPSJudW1iZXIiIGRhdGEtc2VtYW50aWMtcm9sZT0iaW50ZWdlciIgZGF0YS1zZW1hbnRpYy1mb250PSJub3JtYWwiIGRhdGEtc2VtYW50aWMtaWQ9IjMwIiBkYXRhLXNlbWFudGljLXBhcmVudD0iMzEiIGRhdGEtc2VtYW50aWMtY29tcGxleGl0eT0iMiI+MzY1PC9tbj4NCiAgICAgICAgICAgICAgICAgICAgICAgIDwvbWZyYWM+DQogICAgICAgICAgICAgICAgICAgICAgPC9tYWN0aW9uPg0KICAgICAgICAgICAgICAgICAgICA8L21yb3c+DQogICAgICAgICAgICAgICAgICA8L21yb3c+DQogICAgICAgICAgICAgICAgPC9tYWN0aW9uPg0KICAgICAgICAgICAgICAgIDxtbyBzdHJldGNoeT0iZmFsc2UiIGRhdGEtc2VtYW50aWMtdHlwZT0iZmVuY2UiIGRhdGEtc2VtYW50aWMtcm9sZT0iY2xvc2UiIGRhdGEtc2VtYW50aWMtaWQ9IjMyIiBkYXRhLXNlbWFudGljLXBhcmVudD0iMzciIGRhdGEtc2VtYW50aWMtb3BlcmF0b3I9ImZlbmNlZCIgZGF0YS1zZW1hbnRpYy1jb21wbGV4aXR5PSIxIj4pPC9tbz4NCiAgICAgICAgICAgICAgPC9tcm93Pg0KICAgICAgICAgICAgPC9tcm93Pg0KICAgICAgICAgIDwvbXJvdz4NCiAgICAgICAgPC9tYWN0aW9uPg0KICAgICAgPC9tcm93Pg0KICAgIDwvbXJvdz4NCiAgPC9tYWN0aW9uPg0KPC9tYXRoPg0KDQoNCmBgYHtyfQ0KZXhhY3RfcHJvYiA8LSBmdW5jdGlvbihuKXsNCiAgcHJvYl91bmlxdWUgPC0gc2VxKDM2NSwgMzY1LW4rMSkvMzY1DQogICMgdGhlIHByb2JhYmlsdHkgb2YgYW4gZXZlbnQgaGFwcGVuaW5nIGlzIDEgbWludXMgdGhlIHByb2JhYmlsaXR5IG9mIHRoZSBldmVudCBub3QgaGFwcGVuaW5nDQogIDEgLSBwcm9kKCBwcm9iX3VuaXF1ZSkNCn0NCmVwcm9iIDwtIHNhcHBseShuLCBleGFjdF9wcm9iKQ0KIyBDb21wYXJlIG1vbnRlIGNhcmxvIHBsb3QgdG8gZXhhY3QgcHJvYmFiaWx0eSBwbG90DQpwbG90KG4sIHByb2IpDQpsaW5lcyhuLCBlcHJvYiwgY29sID0gJ3JlZCcpDQpgYGANCg0K